'''
[Abstract]
Create a python program that detects objects in JPEG images using the trained AI model of "MobileNetV3 SSD-Lite".
"MobileNetV3 SSD-Lite" の学習済みAIモデルを使用して、JPEG画像を対象に物体検知する Python プログラムを作成します。
[Details]
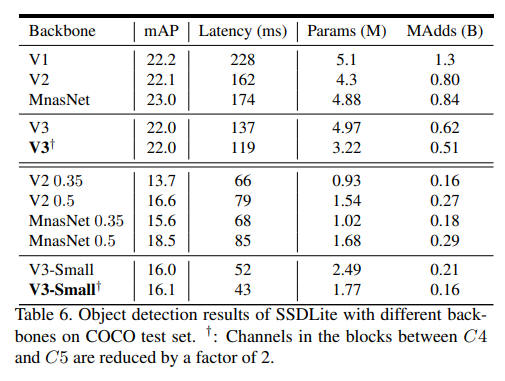
This program uses pytorch "ssdlite320_mobilenet_v3_large" and pre-trained model.
The program detects 91 classes because the trained model is trained using the COCO dataset.
When you run this program for the first time, you will have to wait a lot of time to start the program, as it downloads the trained model.
このプログラムは pytorch の "ssdlite320_mobilenet_v3_large" および 学習済みモデルを使用します。
学習済みモデルは COCO dataset を使って学習しているので、このプログラムは91クラスを検知します。
このプログラムを初めて実行するとき、このプログラムは学習済みモデルのダウンロードを行うため、あなたはプログラム起動に多くの時間を待つ必要があるでしょう。
[Library install]
cv2: pip install opencv-python
pytorch: pip install torch torchvision torchaudio
[Reference URL]
https://pytorch.org/vision/main/models.html#object-detection
https://pytorch.org/vision/0.11/auto_examples/plot_visualization_utils.html#visualizing-bounding-boxes
'''
from pathlib import Path
from torchvision.io.image import read_image
from torchvision.models.detection import ssdlite320_mobilenet_v3_large, SSDLite320_MobileNet_V3_Large_Weights
from torchvision.utils import draw_bounding_boxes
from torchvision.transforms.functional import to_pil_image
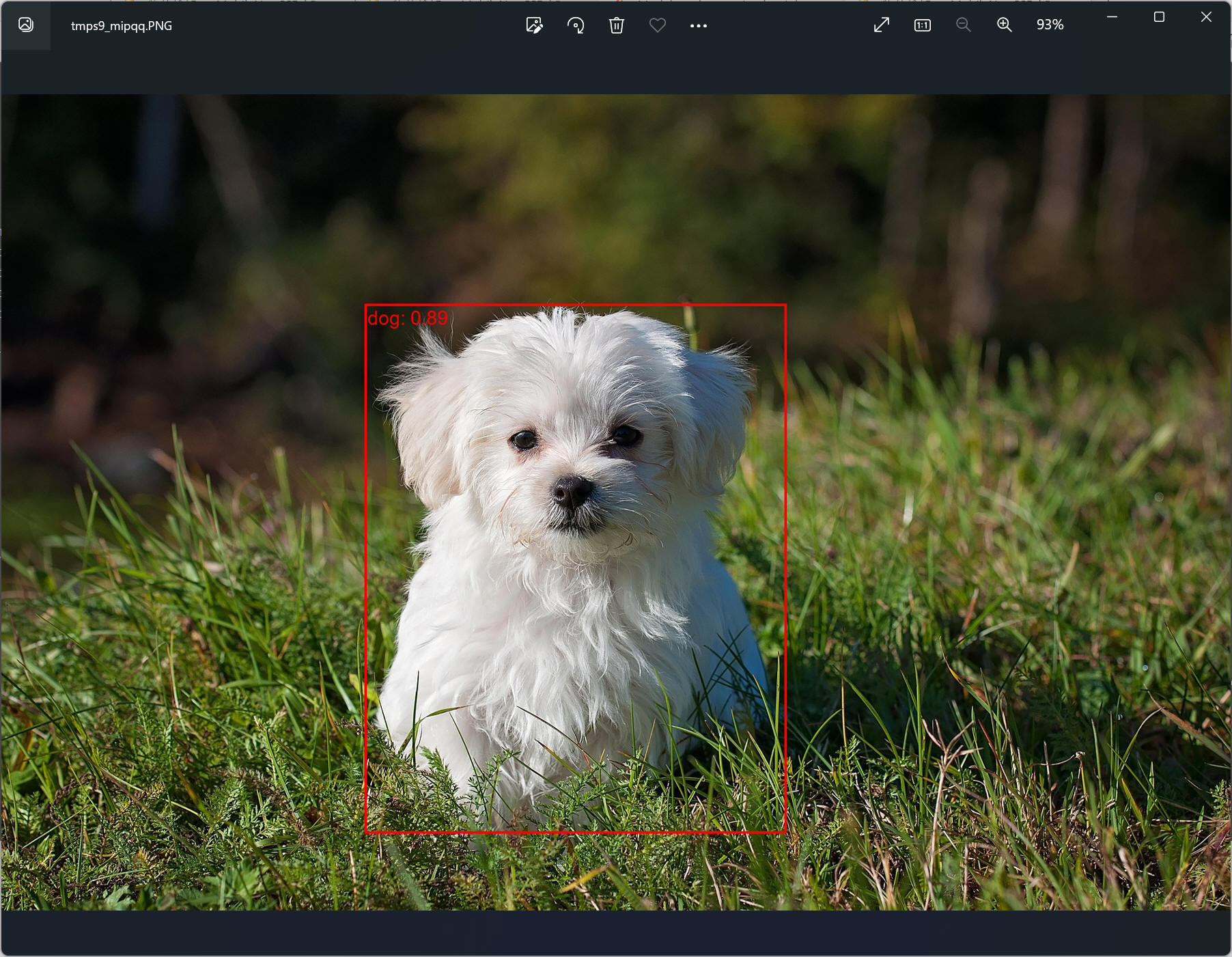
img = read_image(str(Path('assets') / 'dog1.jpg'))
# Step 1: Initialize model with the best available weights
weights = SSDLite320_MobileNet_V3_Large_Weights.DEFAULT
model = ssdlite320_mobilenet_v3_large(weights=weights)
model = model.eval()
# Step 2: Initialize the inference transforms
preprocess = weights.transforms()
# Step 3: Apply inference preprocessing transforms
batch = [preprocess(img)]
# Step 4: Use the model and visualize the prediction
prediction = model(batch)[0]
score_threshold = 0.5
labels = [weights.meta["categories"][class_index] + f": {score_int:.2f}" for class_index, score_int in zip(prediction["labels"], prediction["scores"]) if score_int > score_threshold]
boxes = prediction["boxes"][prediction["scores"] > score_threshold]
box = draw_bounding_boxes(img, boxes=boxes,
labels=labels,
colors="red",
width=4,
font='arial.ttf', font_size=30)
im = to_pil_image(box.detach())
im.show()
'''
[Abstract]
Create a python program to detect objects in the camera live video using the trained AI model of "MobileNetV3 SSD-Lite".
"MobileNetV3 SSD-Lite" の学習済みAIモデルを使用して、カメラライブ映像を物体検知する Python プログラムを作成してみます。
[Details]
This program uses pytorch "ssdlite320_mobilenet_v3_large" and pre-trained model.
The program detects 91 classes because the trained model is trained using the COCO dataset.
When you run this program for the first time, you will have to wait a lot of time to start the program, as it downloads the trained model.
このプログラムは pytorch の "ssdlite320_mobilenet_v3_large" および 学習済みモデルを使用します。
学習済みモデルは COCO dataset を使って学習しているので、このプログラムは91クラスを検知します。
このプログラムを始めて実行するとき、このプログラムは学習済みモデルのダウンロードを行うため、あなたはプログラム起動に多くの時間を待つ必要があるでしょう。
[Library install]
cv2: pip install opencv-python
pytorch: pip install torch torchvision torchaudio
'''
import cv2
import torch
from torchvision.models.detection import ssdlite320_mobilenet_v3_large, SSDLite320_MobileNet_V3_Large_Weights
from torchvision.transforms.functional import convert_image_dtype
from torchvision import transforms
# Step 1: Initialize model with the best available weights
weights = SSDLite320_MobileNet_V3_Large_Weights.DEFAULT
model = ssdlite320_mobilenet_v3_large(weights=weights)
model = model.eval()
# Step 2: Initialize the inference transforms
preprocess = weights.transforms()
# Initialize variables.
cap = cv2.VideoCapture(0) # Capture from camera.
#cap.set(3, 1920) # Set video stream frame width. Remove '#' and change the value according to your needs.
#cap.set(4, 1080) # Set video stream frame height. Remove '#' and change the value according to your needs.
winname = "Annotated" # Window title.
# Exception definition.
BackendError = type('BackendError', (Exception,), {})
def IsWindowVisible(winname):
'''
[Abstract]
Check if the target window exists.
対象ウィンドウが存在するかを確認する。
[Param]
winname : Window title
[Return]
True : exist
存在する
False : not exist
存在しない
[Exception]
BackendError :
'''
try:
ret = cv2.getWindowProperty(winname, cv2.WND_PROP_VISIBLE)
if ret == -1:
raise BackendError('Use Qt as backend to check whether window is visible or not.')
return bool(ret)
except cv2.error:
return False
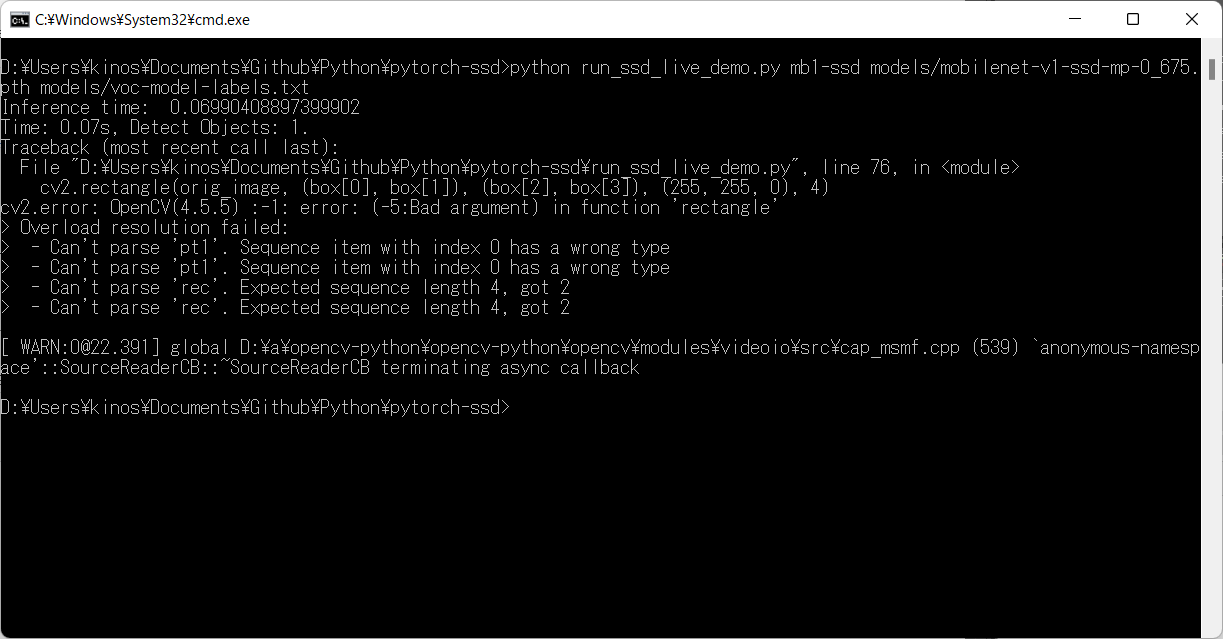
while True:
# Capture image by opencv.
ret, orig_image = cap.read()
if orig_image is None:
continue
# Convert image from BGR to RGB.
rgb_image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB)
# Convert image from numpy.ndarray to torchvision image format.
rgb_image = rgb_image.transpose((2, 0, 1))
rgb_image = rgb_image / 255.0
rgb_image = torch.FloatTensor(rgb_image)
# Step 3: Apply inference preprocessing transforms
batch = [preprocess(rgb_image)]
# Step 4: Use the model and visualize the prediction
with torch.no_grad():
prediction = model(batch)[0]
score_threshold = 0.5
labels = [weights.meta["categories"][class_index] + f": {score_int:.2f}" for class_index, score_int in zip(prediction["labels"], prediction["scores"]) if score_int > score_threshold]
boxes = prediction["boxes"][prediction["scores"] > score_threshold]
# Draw result.
for box, label in zip(boxes, labels):
cv2.rectangle(
orig_image, # Image.
(int(box[0]), int(box[1])), # Vertex of the rectangle.
(int(box[2]), int(box[3])), # Vertex of the rectangle opposite to pt1.
(255, 255, 0), # Color.
4 ) # Line type.
cv2.putText(
orig_image, # Image.
label, # Text string to drawn.
(int(box[0])+20, int(box[1])+40), # Bottom-left corner of the text string in the image.
cv2.FONT_HERSHEY_SIMPLEX, # Font face. - フォント種別
0.8, # Font scale.
(255, 0, 255), # Color.
2) # Line type.
# Display video.
cv2.imshow(winname, orig_image)
# Press the "q" key to finish.
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Exit the program if there is no specified window.
if not IsWindowVisible(winname):
break
cap.release()
cv2.destroyAllWindows()
'''
[Abstract]
Create a python program to detect objects in the camera live video using the trained AI model of "MobileNetV3 SSD-Lite".
"MobileNetV3 SSD-Lite" の学習済みAIモデルを使用して、カメラライブ映像を物体検知する Python プログラムを作成してみます。
[Details]
This program uses pytorch "ssdlite320_mobilenet_v3_large" and pre-trained model.
The program detects 91 classes because the trained model is trained using the COCO dataset.
When you run this program for the first time, you will have to wait a lot of time to start the program, as it downloads the trained model.
このプログラムは pytorch の "ssdlite320_mobilenet_v3_large" および 学習済みモデルを使用します。
学習済みモデルは COCO dataset を使って学習しているので、このプログラムは91クラスを検知します。
このプログラムを始めて実行するとき、このプログラムは学習済みモデルのダウンロードを行うため、あなたはプログラム起動に多くの時間を待つ必要があるでしょう。
[Library install]
cv2: pip install opencv-python
pytorch: pip install torch torchvision torchaudio
'''
import cv2
import torch
from torchvision.models.detection import ssdlite320_mobilenet_v3_large, SSDLite320_MobileNet_V3_Large_Weights
from torchvision.transforms.functional import convert_image_dtype
from torchvision import transforms
# Initialize variables.
user_id = "user-id" # Change to match your camera settinguser_pw = "password" # Change to match your camera settinghost = "192.168.0.10" # Change to match your camera settingresolution = "1920x1080" # Resolutionframerate = 5 # Framerate
winname = "Annotated" # Window title.
# Step 1: Initialize model with the best available weights
weights = SSDLite320_MobileNet_V3_Large_Weights.DEFAULT
model = ssdlite320_mobilenet_v3_large(weights=weights)
model = model.eval()
# Step 2: Initialize the inference transforms
preprocess = weights.transforms()
# Capture from camera.
url = f"rtsp://{user_id}:{user_pw}@{host}/MediaInput/stream_1" # H.264/H.265#url = f"http://{user_id}:{user_pw}@{host}/cgi-bin/nphMotionJpeg?Resolution={resolution}&Quality=Standard&Framerate={framerate}" # MJPEGcap = cv2.VideoCapture(url)
# Exception definition.
BackendError = type('BackendError', (Exception,), {})
def IsWindowVisible(winname):
'''
[Abstract]
Check if the target window exists.
対象ウィンドウが存在するかを確認する。
[Param]
winname : Window title
[Return]
True : exist
存在する
False : not exist
存在しない
[Exception]
BackendError :
'''
try:
ret = cv2.getWindowProperty(winname, cv2.WND_PROP_VISIBLE)
if ret == -1:
raise BackendError('Use Qt as backend to check whether window is visible or not.')
return bool(ret)
except cv2.error:
return False
while True:
# Capture image by opencv.
ret, orig_image = cap.read()
if orig_image is None:
continue
# Convert image from BGR to RGB.
rgb_image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB)
# Convert image from numpy.ndarray to torchvision image format.
rgb_image = rgb_image.transpose((2, 0, 1))
rgb_image = rgb_image / 255.0
rgb_image = torch.FloatTensor(rgb_image)
# Step 3: Apply inference preprocessing transforms
batch = [preprocess(rgb_image)]
# Step 4: Use the model and visualize the prediction
with torch.no_grad():
prediction = model(batch)[0]
score_threshold = 0.5
labels = [weights.meta["categories"][class_index] + f": {score_int:.2f}" for class_index, score_int in zip(prediction["labels"], prediction["scores"]) if score_int > score_threshold]
boxes = prediction["boxes"][prediction["scores"] > score_threshold]
# Draw result.
for box, label in zip(boxes, labels):
cv2.rectangle(
orig_image, # Image.
(int(box[0]), int(box[1])), # Vertex of the rectangle.
(int(box[2]), int(box[3])), # Vertex of the rectangle opposite to pt1.
(255, 255, 0), # Color.
4 ) # Line type.
cv2.putText(
orig_image, # Image.
label, # Text string to drawn.
(int(box[0])+20, int(box[1])+40), # Bottom-left corner of the text string in the image.
cv2.FONT_HERSHEY_SIMPLEX, # Font face. - フォント種別
0.8, # Font scale.
(255, 0, 255), # Color.
2) # Line type.
# Display video.
cv2.imshow(winname, orig_image)
# Press the "q" key to finish.
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Exit the program if there is no specified window.
if not IsWindowVisible(winname):
break
cap.release()
cv2.destroyAllWindows()
$ cd data
$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
$ tar -xvf VOCtrainval_11-May-2012.tar
$ tar -xvf VOCtrainval_06-Nov-2007.tar
$ tar -xvf VOCtest_06-Nov-2007.tar
■Windows の場合
Windows に標準では wget コマンドは無いため上記を実行してもエラーになります。ここでは、wget の代わりに bitsadmin
コマンドで代用する方法を紹介します。
Licensed under the Apache License, Version
2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
Unless required by
applicable law or agreed to in writing, software distributed under the
License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
CONDITIONS OF ANY KIND, either express or implied. See the License for
the specific language governing permissions and limitations under the
License.
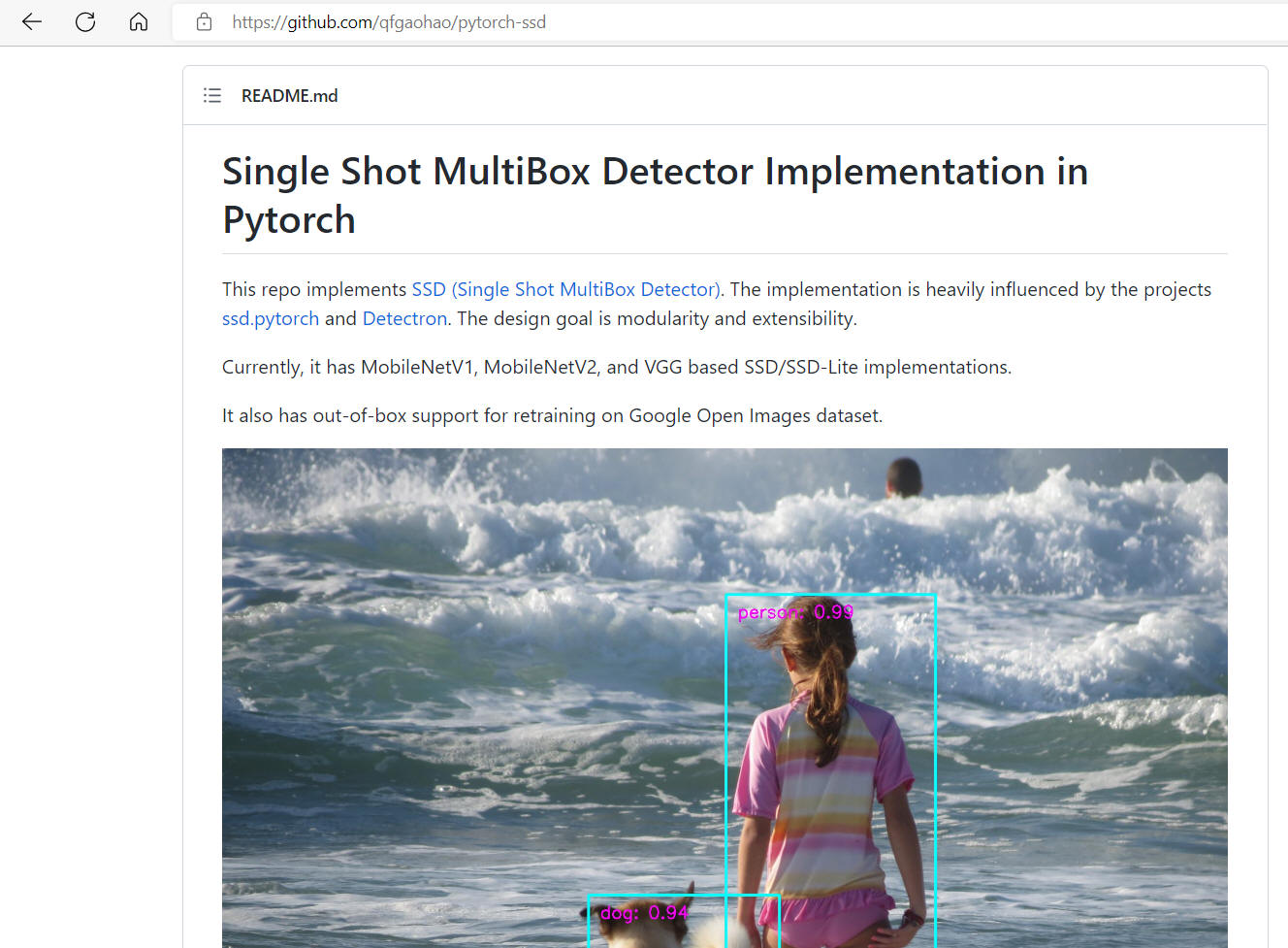
[2] qfgaohao/pytorch-ssd: MobileNetV1, MobileNetV2, VGG based
SSD/SSD-lite implementation in Pytorch 1.0 / Pytorch 0.4. Out-of-box
support for retraining on Open Images dataset. ONNX and Caffe2 support.
Experiment Ideas like CoordConv. (github.com)
https://github.com/qfgaohao/pytorch-ssd