5. 学習
[概要]
あなたが用意した画像データを使って独自の MobileNet-SSD 学習データを作成する手順を紹介します。
以下の順序で進めたいと思います。
- 使用する AI モデル紹介に記載のチュートリアルに従って学習を行ってみる
- 独自の画像を収集し、ツールを使って自身でアノテーションを行い、これら画像とアノテーションデータを使って学習を行ってみる
- 自身で作成した学習データとカメラを使って物体検知を行ってみる
5-1. まずはやってみる (Open Images)
[概要]
今回も pytorch-ssd で紹介されているプログラムと内容を使って進めます。
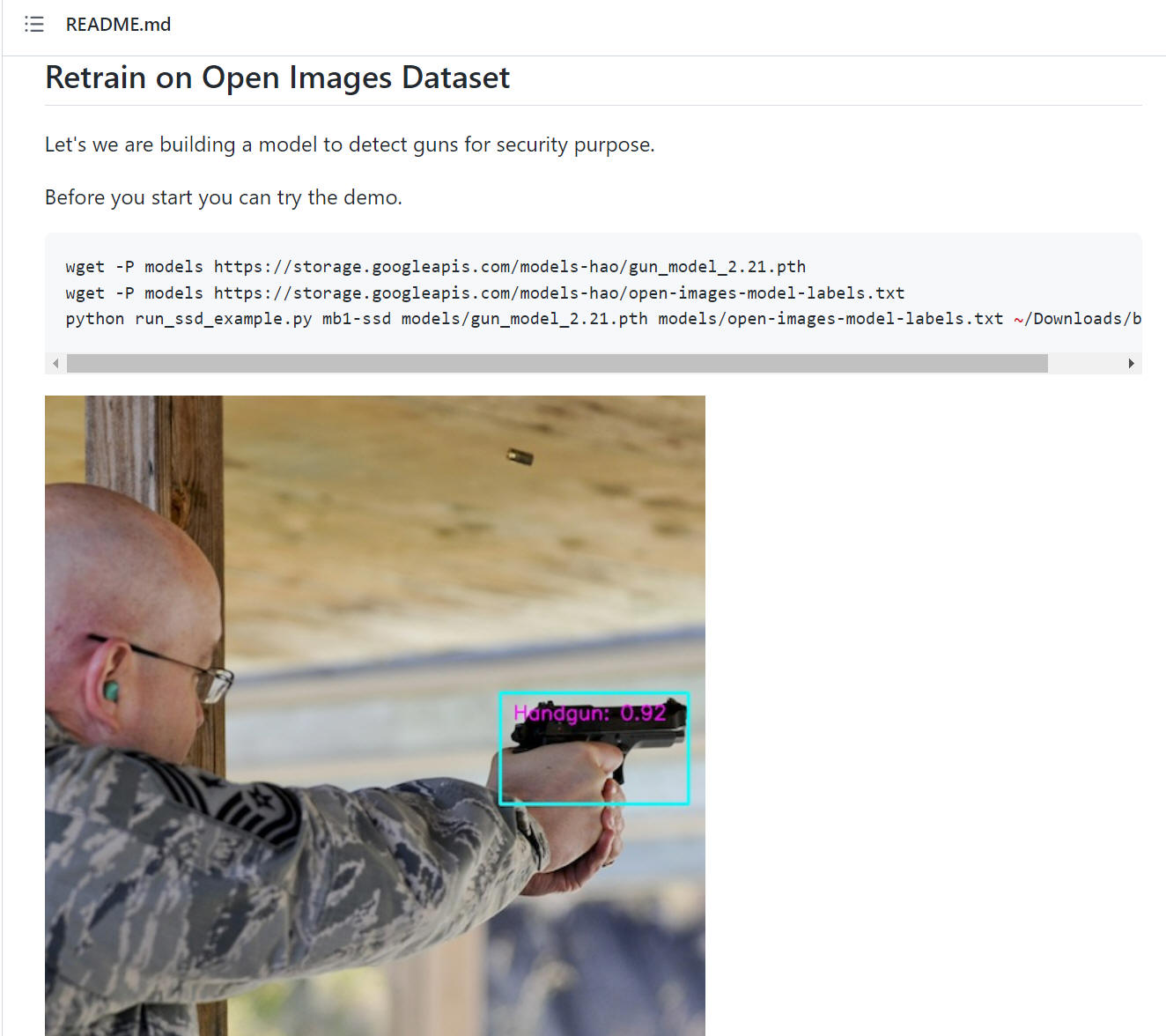
ここでは "Retrain on Open Images Dataset" で説明されている記述に従って学習を実際にやってみます。 Python プログラムはもちろん、画像データおよびアノテーションデータなど必要なすべての情報を提供いただいています。 こちらの記事は MobileNet-SSD の学習方法を学ぶ最初の教材として最適な内容です。
使用する学習データ数は以下の通りです。
| Class name | Train | Test |
|---|---|---|
| Hundgun | 545 | 68 |
| Shotgun | 416 | 55 |
| 合計 | 961 | 123 |
NOTE
"Hundgun" と "Shutgun" 2クラスで再学習を行う、という内容です。
[評価環境]
| 言語 : | Python, | 3.10.7 3.7.9 |
| PyTorch, | 1.12.1+cpu | |
| OS : | Windows 11 home, | 22H2 |
5-1-1. 準備
1. pytorch-ssd をクローンします。(ここまで読まれた方は恐らく完了しているでしょう)
こちら の記載を参考に実施します。
2. 以下のコマンドで必要なライブラリーをインストールします。これらは後述の "open_images_downloader.py" で使用しているライブラリです。
pip3 install boto3 pandas
3. ディレクトリ移動
ターミナルソフトを起動後、 pytorch-ssd をクローンしたフォルダへ移動("cd pytorch-ssd" など)します。
または Explorer で目的フォルダを開いた後、Explorer のアドレスエリアで "cmd" + [Enter] します。
4. まずは再学習済みデータを使ってデモ動作してみます。
下記 Google Drive を開いて、"gun_model_2.21.pth" および "open-images-model-labels.txt" の2つのファイルを取得して models フォルダに保存します。
https://drive.google.com/drive/folders/1pKn-RifvJGWiOx0ZCRLtCXM5GT5lAluu
NOTE
2023/3/11 の pytorch-ssd 更新によりモデルファイルの取得方法が変更になりました。
"Retrain on Open Images Dataset" の説明では最初に以下の通り記載されています。これを実行します。
$ python run_ssd_example.py mb1-ssd models/gun_model_2.21.pth models/open-images-model-labels.txt ~/Downloads/big.JPG
※ "big.JPG" ファイルは提供されてないようです。上記コマンドのテストに GUN の評価画像ファイルを必要としますので、ご自身で評価画像を入手するか、もしくは後述の「5. Download data」を実施後にこの画像ファイルを使って実験する、などする必要があります。
5. Download data
インターネットから学習データ一式を取得します。
■Linux の場合
"Download data"では下記のように書いています。Linux 環境ではこれを実行します。
$ python open_images_downloader.py --root ~/data/open_images --class_names "Handgun,Shotgun" --num_workers 20
■Windows の場合
Windows 環境ではエラーになるので、"--root" の指定フォルダを下記のように変更すると無事ダウンロードすることができました。JPEG画像がそれなりの枚数あるので、私の環境で全データのダウンロードに5分ぐらいかかりました。
$ python open_images_downloader.py --root ./data/open_images --class_names "Handgun,Shotgun" --num_workers 20
6. 確認
ダウンロード完了後の様子を下図に示します。
指定したフォルダ "./data/open_images" の中に7つの csv ファイルと、3つのフォルダ(test, train, validation)に多くのJPEG画像ファイルを保存していることがわかります。
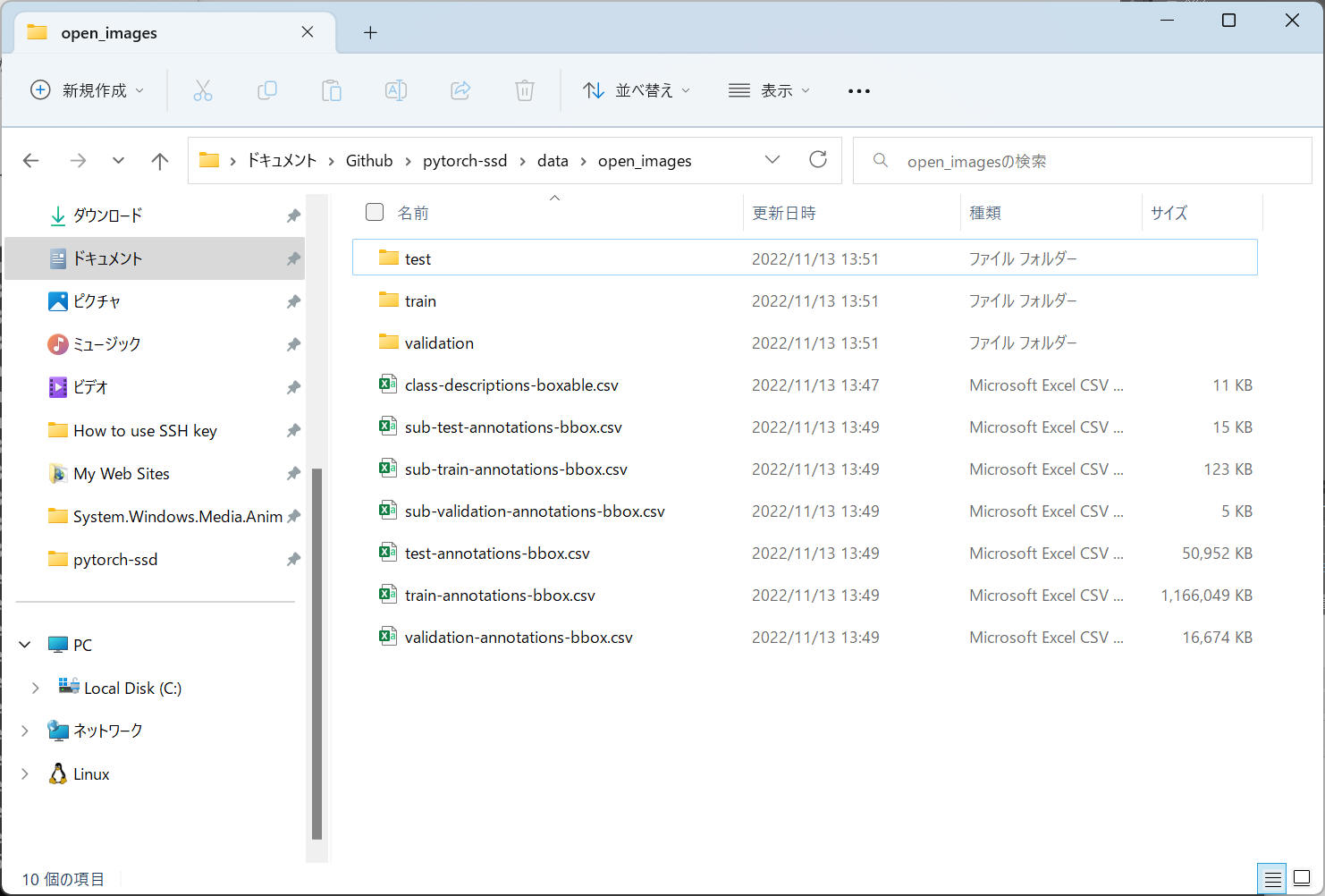
"test" フォルダ内の様子です。
"class-descriptions-boxable.csv" の様子です。分類するクラス一覧を記述しているようです。
"Handgun", "Shot gun" も含んでいました。私がダウンロードしたデータでは 601 種類のクラスを記録していました。
先ほどの手順では "Handgun,Shotgun" を指定してデータをダウンロードしましたが、こちらに記録されているクラスを指定して画像およびアノテーションデータをダウンロードできそうです。

"sub-test-annotations-bbox.csv" の様子です。画像データおよびアノテーションデータ一覧のようです。
XMin,XMax,YMin,YMax の4つは、画像データ上の物体の位置を示しています。それぞれ 0.0~1.0 の範囲で表記するルールとなっているため画像の解像度に影響されません。
LabelName, id, に記載の情報は、ClassName と紐づけられている情報のようです。"class-descriptions-boxable.csv" で例えば "/m/0gxl3" を検索すると "Handgun" となっています。

以上のような構成でデータを準備することで、あたなや私が独自に学習したい物体と画像についても同様に AI 学習データを作成できることがわかりました。
7. 学習済みモデルを保存
本ページを上から順に進めてきた人たちは既に models フォルダに学習済みモデルデータを保存済みと思います。まだの方は、こちらに記載の内容に従って "mobilenet-v1-ssd-mp-0_675.pth" をダウンロードしてください。
5-1-2. 学習
8. Retrain (再学習)を実行します
■Linux の場合
資料では下記のように書いています。Linux 環境ではこれを実行します。
$ python train_ssd.py --dataset_type open_images --datasets ~/data/open_images --net mb1-ssd --pretrained_ssd models/mobilenet-v1-ssd-mp-0_675.pth --scheduler cosine --lr 0.01 --t_max 100 --validation_epochs 5 --num_epochs 100 --base_net_lr 0.001 --batch_size 5
■Windows の場合
Windows 環境では --datasets ~/data/open_images の部分を実際の環境に合わせて修正します。ここでは下記コマンドへ修正して実行してみます。
$ python train_ssd.py --dataset_type open_images --datasets ./data/open_images --net mb1-ssd --pretrained_ssd models/mobilenet-v1-ssd-mp-0_675.pth --scheduler cosine --lr 0.01 --t_max 100 --validation_epochs 5 --num_epochs 100 --base_net_lr 0.001 --batch_size 5
以下、上記コマンド実行後のコンソール出力内容です。
データ読み込みまでは問題なくできていそうですが、"Start training from epoch 0." の後で1つの警告と1つのエラーを出力して停止しました。これら主力部分を赤字で表記します。
2022-11-13 15:04:07,989 - root - INFO - Namespace(dataset_type='open_images', datasets=['./data/open_images'], validation_dataset=None, balance_data=False, net='mb1-ssd', freeze_base_net=False, freeze_net=False, mb2_width_mult=1.0, lr=0.01, momentum=0.9, weight_decay=0.0005, gamma=0.1, base_net_lr=0.001, extra_layers_lr=None, base_net=None, pretrained_ssd='models/mobilenet-v1-ssd-mp-0_675.pth', resume=None, scheduler='cosine', milestones='80,100', t_max=100.0, batch_size=5, num_epochs=100, num_workers=4, validation_epochs=5, debug_steps=100, use_cuda=True, checkpoint_folder='models/') 2022-11-13 15:04:07,989 - root - INFO - Prepare training datasets. 2022-11-13 15:04:08,277 - root - INFO - Dataset Summary:Number of Images: 961 Minimum Number of Images for a Class: -1 Label Distribution: Handgun: 727 Shotgun: 580 2022-11-13 15:04:08,282 - root - INFO - Stored labels into file models/open-images-model-labels.txt. 2022-11-13 15:04:08,282 - root - INFO - Train dataset size: 961 2022-11-13 15:04:08,282 - root - INFO - Prepare Validation datasets. 2022-11-13 15:04:08,302 - root - INFO - Dataset Summary:Number of Images: 123 Minimum Number of Images for a Class: -1 Label Distribution: Handgun: 81 Shotgun: 66 2022-11-13 15:04:08,302 - root - INFO - validation dataset size: 123 2022-11-13 15:04:08,302 - root - INFO - Build network. 2022-11-13 15:04:08,349 - root - INFO - Init from pretrained ssd models/mobilenet-v1-ssd-mp-0_675.pth 2022-11-13 15:04:08,391 - root - INFO - Took 0.04 seconds to load the model. 2022-11-13 15:04:08,396 - root - INFO - Learning rate: 0.01, Base net learning rate: 0.001, Extra Layers learning rate: 0.01. 2022-11-13 15:04:08,396 - root - INFO - Uses CosineAnnealingLR scheduler. 2022-11-13 15:04:08,396 - root - INFO - Start training from epoch 0. C:\Users\foo\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\optim\lr_scheduler.py:131: UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the opposite order: `optimizer.step()` before `lr_scheduler.step()`. Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate warnings.warn("Detected call of `lr_scheduler.step()` before `optimizer.step()`. " Traceback (most recent call last): File "C:\Users\kinos\Documents\Github\pytorch-ssd\train_ssd.py", line 325, in <module> train(train_loader, net, criterion, optimizer, File "C:\Users\kinos\Documents\Github\pytorch-ssd\train_ssd.py", line 116, in train for i, data in enumerate(loader): File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\utils\data\dataloader.py", line 444, in __iter__ return self._get_iterator() File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\utils\data\dataloader.py", line 390, in _get_iterator return _MultiProcessingDataLoaderIter(self) File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\utils\data\dataloader.py", line 1077, in __init__ w.start() File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\process.py", line 121, in start self._popen = self._Popen(self) File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\context.py", line 224, in _Popen return _default_context.get_context().Process._Popen(process_obj) File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\context.py", line 336, in _Popen return Popen(process_obj) File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\popen_spawn_win32.py", line 93, in __init__ reduction.dump(process_obj, to_child) File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\reduction.py", line 60, in dump ForkingPickler(file, protocol).dump(obj) AttributeError: Can't pickle local object 'TrainAugmentation.__init__.<locals>.<lambda>' C:\Users\kinos\Documents\Github\pytorch-ssd>Traceback (most recent call last): File "<string>", line 1, in <module> File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\spawn.py", line 116, in spawn_main exitcode = _main(fd, parent_sentinel) File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\spawn.py", line 126, in _main self = reduction.pickle.load(from_parent) EOFError: Ran out of input
"UserWarning: Detected call of `lr_scheduler.step()` before
`optimizer.step()`. In PyTorch 1.1.0 and later, you should call them in the
opposite order: `optimizer.step()` before `lr_scheduler.step()`.
Failure to do this will result in PyTorch skipping the first value of the
learning rate schedule. See more details at
https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Detected call of `lr_scheduler.step()` before
`optimizer.step()`." について
こちらは、上記文章中に記載の通り "PyTorch 1.1.0" 以降での仕様変更に伴う警告のようです。
ソースファイル "train_ssd.py" 中を 323行目 周辺について、下記のとおり変更することで警告されなくなります。
(修正後)
for epoch in range(last_epoch + 1, args.num_epochs):
train(train_loader, net, criterion, optimizer,
device=DEVICE, debug_steps=args.debug_steps, epoch=epoch)
scheduler.step()
if epoch % args.validation_epochs == 0 or epoch == args.num_epochs - 1:
val_loss, val_regression_loss, val_classification_loss = test(val_loader, net, criterion, DEVICE)
logging.info(
f"Epoch: {epoch}, " +
f"Validation Loss: {val_loss:.4f}, " +
f"Validation Regression Loss {val_regression_loss:.4f}, " +
f"Validation Classification Loss: {val_classification_loss:.4f}"
)
model_path = os.path.join(args.checkpoint_folder, f"{args.net}-Epoch-{epoch}-Loss-{val_loss}.pth")
net.save(model_path)
logging.info(f"Saved model {model_path}")
(修正前)
for epoch in range(last_epoch + 1, args.num_epochs):
scheduler.step()
train(train_loader, net, criterion, optimizer,
device=DEVICE, debug_steps=args.debug_steps, epoch=epoch)
if epoch % args.validation_epochs == 0 or epoch == args.num_epochs - 1:
val_loss, val_regression_loss, val_classification_loss = test(val_loader, net, criterion, DEVICE)
logging.info(
f"Epoch: {epoch}, " +
f"Validation Loss: {val_loss:.4f}, " +
f"Validation Regression Loss {val_regression_loss:.4f}, " +
f"Validation Classification Loss: {val_classification_loss:.4f}"
)
model_path = os.path.join(args.checkpoint_folder, f"{args.net}-Epoch-{epoch}-Loss-{val_loss}.pth")
net.save(model_path)
logging.info(f"Saved model {model_path}")
(修正後)のプログラムを再度実行すると、とりあえず1つ目の警告(UserWarning)は消えました。
C:\Users\foo\Documents\Github\pytorch-ssd>python train_ssd.py --dataset_type open_images --datasets ./data/open_images --net mb1-ssd --pretrained_ssd models/mobilenet-v1-ssd-mp-0_675.pth --scheduler cosine --lr 0.01 --t_max 100 --validation_epochs 5 --num_epochs 100 --base_net_lr 0.001 --batch_size 5
2022-11-13 16:35:24,380 - root - INFO - Namespace(dataset_type='open_images', datasets=['./data/open_images'], validation_dataset=None, balance_data=False, net='mb1-ssd', freeze_base_net=False, freeze_net=False, mb2_width_mult=1.0, lr=0.01, momentum=0.9, weight_decay=0.0005, gamma=0.1, base_net_lr=0.001, extra_layers_lr=None, base_net=None, pretrained_ssd='models/mobilenet-v1-ssd-mp-0_675.pth', resume=None, scheduler='cosine', milestones='80,100', t_max=100.0, batch_size=5, num_epochs=100, num_workers=4, validation_epochs=5, debug_steps=100, use_cuda=True, checkpoint_folder='models/')
2022-11-13 16:35:24,380 - root - INFO - Prepare training datasets.
2022-11-13 16:35:24,662 - root - INFO - Dataset Summary:Number of Images: 961
Minimum Number of Images for a Class: -1
Label Distribution:
Handgun: 727
Shotgun: 580
2022-11-13 16:35:24,662 - root - INFO - Stored labels into file models/open-images-model-labels.txt.
2022-11-13 16:35:24,662 - root - INFO - Train dataset size: 961
2022-11-13 16:35:24,662 - root - INFO - Prepare Validation datasets.
2022-11-13 16:35:24,693 - root - INFO - Dataset Summary:Number of Images: 123
Minimum Number of Images for a Class: -1
Label Distribution:
Handgun: 81
Shotgun: 66
2022-11-13 16:35:24,693 - root - INFO - validation dataset size: 123
2022-11-13 16:35:24,693 - root - INFO - Build network.
2022-11-13 16:35:24,743 - root - INFO - Init from pretrained ssd models/mobilenet-v1-ssd-mp-0_675.pth
2022-11-13 16:35:24,774 - root - INFO - Took 0.03 seconds to load the model.
2022-11-13 16:35:24,789 - root - INFO - Learning rate: 0.01, Base net learning rate: 0.001, Extra Layers learning rate: 0.01.
2022-11-13 16:35:24,789 - root - INFO - Uses CosineAnnealingLR scheduler.
2022-11-13 16:35:24,789 - root - INFO - Start training from epoch 0.
Traceback (most recent call last):
File "C:\Users\kinos\Documents\Github\pytorch-ssd\train_ssd.py", line 324, in <module>
train(train_loader, net, criterion, optimizer,
File "C:\Users\kinos\Documents\Github\pytorch-ssd\train_ssd.py", line 116, in train
for i, data in enumerate(loader):
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\utils\data\dataloader.py", line 444, in __iter__
return self._get_iterator()
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\utils\data\dataloader.py", line 390, in _get_iterator
return _MultiProcessingDataLoaderIter(self)
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\utils\data\dataloader.py", line 1077, in __init__
w.start()
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\process.py", line 121, in start
self._popen = self._Popen(self)
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\context.py", line 336, in _Popen
return Popen(process_obj)
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\popen_spawn_win32.py", line 93, in __init__
reduction.dump(process_obj, to_child)
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
AttributeError: Can't pickle local object 'TrainAugmentation.__init__.<locals>.<lambda>'
C:\Users\kinos\Documents\Github\pytorch-ssd>Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "C:\Users\kinos\AppData\Local\Programs\Python\Python310\lib\multiprocessing\spawn.py", line 126, in _main
self = reduction.pickle.load(from_parent)
EOFError: Ran out of input
残るエラー "AttributeError: Can't pickle local object 'TrainAugmentation.__init__.<locals>.<lambda>'" を解決します。
この問題を解決している記事がありました。Linux 環境では発生しない Windows 環境固有の問題と思われます。
NOTE
「AttributeError: Can't pickle local object 'TrainAugmentation.__init__.<locals>.<lambda>'」 について、下記ページで修正方法を紹介しています。
上記URLに記載の内容に従って修正した後の「vision/ssd/data_preprocessing.py」を以下に記載します。
修正した場所を色付けしています。
"vision/ssd/data_preprocessing.py"
from ..transforms.transforms import * class ScaleByStd: def __init__(self, std: float): self.std = std def __call__(self, img, boxes=None, labels=None): return (img / self.std, boxes, labels) class TrainAugmentation: def __init__(self, size, mean=0, std=1.0): """ Args: size: the size the of final image. mean: mean pixel value per channel. """ self.mean = mean self.size = size self.augment = Compose([ ConvertFromInts(), PhotometricDistort(), Expand(self.mean), RandomSampleCrop(), RandomMirror(), ToPercentCoords(), Resize(self.size), SubtractMeans(self.mean), #lambda img, boxes=None, labels=None: (img / std, boxes, labels), ScaleByStd(std), ToTensor(), ]) def __call__(self, img, boxes, labels): """ Args: img: the output of cv.imread in RGB layout. boxes: boundding boxes in the form of (x1, y1, x2, y2). labels: labels of boxes. """ return self.augment(img, boxes, labels) class TestTransform: def __init__(self, size, mean=0.0, std=1.0): self.transform = Compose([ ToPercentCoords(), Resize(size), SubtractMeans(mean), #lambda img, boxes=None, labels=None: (img / std, boxes, labels), ScaleByStd(std), ToTensor(), ]) def __call__(self, image, boxes, labels): return self.transform(image, boxes, labels) class PredictionTransform: def __init__(self, size, mean=0.0, std=1.0): self.transform = Compose([ Resize(size), SubtractMeans(mean), #lambda img, boxes=None, labels=None: (img / std, boxes, labels), ScaleByStd(std), ToTensor() ]) def __call__(self, image): image, _, _ = self.transform(image) return image
上記修正を行うことで、下記コマンドを正常に実行できるようになりました。
python train_ssd.py --dataset_type open_images --datasets ./data/open_images --net mb1-ssd --pretrained_ssd models/mobilenet-v1-ssd-mp-0_675.pth --scheduler cosine --lr 0.01 --t_max 100 --validation_epochs 5 --num_epochs 100 --base_net_lr 0.001 --batch_size 5
100 Epoch を約5時間半で学習できました。(CPU動作の場合です。GPU動作の場合はもっと高速に学習可能です。)
参考
ゲーミングノートPC環境でも同じ学習を実施。
5時間30分 ⇨ 55分 へ短縮できました。
[環境]
GPU: NVIDIA GeForce GTX 1650 (4GB)
CPU: Intel Core i7-9750H
Cuda: 11.6
Python: 3.10.7
PyToch: 1.12+cu116
OS: Windows 11 home, 22H2
NOTE
"models\open-images-model-labels.txt" は "train_ssd.py" を実行することで自動的に生成されるようにプログラミングされているようです。
dataset_type == 'voc' の場合は "voc-model-labels.txt" を自動的に生成するようです。
2つの生成方法は細かい部分でいろいろと差異がありそうです。詳細については "train_ssd.py" を参照してください。
参考
NOTE
train_ssd.py を正常に実行できるようにはなりましたが、私の環境では下記警告?が頻繁に出力されます。
pytorch-ssd\vision\transforms\transforms.py:247:
VisibleDeprecationWarning: Creating an ndarray from ragged nested
sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with
different lengths or shapes) is deprecated. If you meant to do this, you
must specify 'dtype=object' when creating the ndarray.
mode =
random.choice(self.sample_options)
このままでも正常に動作するようですが、修正したい場合は下記URLの記事を参照。
VisibleDeprecationWarning of augmentations.py · Issue #498 · amdegroot/ssd.pytorch (github.com)
"transforms.py" の 247行目を以下のように修正すればよいようです。
# before mode = random.choice(self.sample_options) # after random_idx = random.randint(0, len(self.sample_options) - 1) mode = self.sample_options[random_idx]
5-1-3. 学習結果と静止画を使って推論
9. 学習したデータとテスト画像を使用して Gun の認識をしてみます。
テスト画像は Pixabay から入手した画像を使用します。
私の学習済みデータ("mb1-ssd-Epoch-99-Loss-2.843603060245514.pth")とサンプル画像("sample_image.jpg")を使った場合の例を以下に記載します。あなたが実際に使用するファイル名およびパスへ修正してください。
$ python run_ssd_example.py mb1-ssd .\models\mb1-ssd-Epoch-99-Loss-2.843603060245514.pth models\open-images-model-labels.txt .\sample_image.jpg
ただし run_ssd_example.py は OpenSSL
のバージョンアップに伴って一部修正する必要があります。修正後のソースコードを下記に示します。
60, 64行目の部分で6か所 int
キャストを追加する必要があります。この修正を行わないとプログラム実行時にエラーとなって動作しませんでした。
"run_ssd_example.py"
from vision.ssd.vgg_ssd import create_vgg_ssd, create_vgg_ssd_predictor
from vision.ssd.mobilenetv1_ssd import create_mobilenetv1_ssd, create_mobilenetv1_ssd_predictor
from vision.ssd.mobilenetv1_ssd_lite import create_mobilenetv1_ssd_lite, create_mobilenetv1_ssd_lite_predictor
from vision.ssd.squeezenet_ssd_lite import create_squeezenet_ssd_lite, create_squeezenet_ssd_lite_predictor
from vision.ssd.mobilenet_v2_ssd_lite import create_mobilenetv2_ssd_lite, create_mobilenetv2_ssd_lite_predictor
from vision.ssd.mobilenetv3_ssd_lite import create_mobilenetv3_large_ssd_lite, create_mobilenetv3_small_ssd_lite
from vision.utils.misc import Timer
import cv2
import sys
if len(sys.argv) < 5:
print('Usage: python run_ssd_example.py <net type> <model path> <label path> <image path>')
sys.exit(0)
net_type = sys.argv[1]
model_path = sys.argv[2]
label_path = sys.argv[3]
image_path = sys.argv[4]
class_names = [name.strip() for name in open(label_path).readlines()]
if net_type == 'vgg16-ssd':
net = create_vgg_ssd(len(class_names), is_test=True)
elif net_type == 'mb1-ssd':
net = create_mobilenetv1_ssd(len(class_names), is_test=True)
elif net_type == 'mb1-ssd-lite':
net = create_mobilenetv1_ssd_lite(len(class_names), is_test=True)
elif net_type == 'mb2-ssd-lite':
net = create_mobilenetv2_ssd_lite(len(class_names), is_test=True)
elif net_type == 'mb3-large-ssd-lite':
net = create_mobilenetv3_large_ssd_lite(len(class_names), is_test=True)
elif net_type == 'mb3-small-ssd-lite':
net = create_mobilenetv3_small_ssd_lite(len(class_names), is_test=True)
elif net_type == 'sq-ssd-lite':
net = create_squeezenet_ssd_lite(len(class_names), is_test=True)
else:
print("The net type is wrong. It should be one of vgg16-ssd, mb1-ssd and mb1-ssd-lite.")
sys.exit(1)
net.load(model_path)
if net_type == 'vgg16-ssd':
predictor = create_vgg_ssd_predictor(net, candidate_size=200)
elif net_type == 'mb1-ssd':
predictor = create_mobilenetv1_ssd_predictor(net, candidate_size=200)
elif net_type == 'mb1-ssd-lite':
predictor = create_mobilenetv1_ssd_lite_predictor(net, candidate_size=200)
elif net_type == 'mb2-ssd-lite' or net_type == "mb3-large-ssd-lite" or net_type == "mb3-small-ssd-lite":
predictor = create_mobilenetv2_ssd_lite_predictor(net, candidate_size=200)
elif net_type == 'sq-ssd-lite':
predictor = create_squeezenet_ssd_lite_predictor(net, candidate_size=200)
else:
predictor = create_vgg_ssd_predictor(net, candidate_size=200)
orig_image = cv2.imread(image_path)
image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB)
boxes, labels, probs = predictor.predict(image, 10, 0.4)
for i in range(boxes.size(0)):
box = boxes[i, :]
cv2.rectangle(orig_image, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])), (255, 255, 0), 4)
#label = f"""{voc_dataset.class_names[labels[i]]}: {probs[i]:.2f}"""
label = f"{class_names[labels[i]]}: {probs[i]:.2f}"
cv2.putText(orig_image, label,
(int(box[0]) + 20, int(box[1]) + 40),
cv2.FONT_HERSHEY_SIMPLEX,
1, # font scale
(255, 0, 255),
2) # line type
path = "run_ssd_example_output.jpg"
cv2.imwrite(path, orig_image)
print(f"Found {len(probs)} objects. The output image is {path}")
以下、テストした結果をいくつか示します。
テスト画像1: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の画像です。ライセンス詳細は "Pixabay License" を参照ください。
["harley-quinn-5391062_1920.jpg"]

テスト画像2: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の画像です。ライセンス詳細は "Pixabay License" を参照ください。
["gun-4222469_1920.jpg"]

テスト画像3: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の画像です。ライセンス詳細は "Pixabay License" を参照ください。
["army-60720_1920.jpg"]

10. "--freeze_net", "--freeze_base_net" を試してみる
ホームページ中に下記説明がありました。

--freeze_net を指定することで "prediction head" を除いて全レイヤーをフリーズと記載されています。俗にいう "転移学習" を行えそうです。これを指定することで演算が軽くなることを期待できます。
--freeze_base_net を指定することで "base net layers" をフリーズするようです。こちらも "転移学習" のバリエーションの一つですね。本ページの例では、MobileNet 部分をフリーズして SSD or SSD-Lite 部分をフリーズしない、と読めば良いのかな、と想像しています。"--freeze_net" よりは学習の演算量が多いはずです。
ここでは学習時間の短縮を目的に、引数 "--freeze_net", "--freeze_base_net" を試してみます。それぞれ 100 Epoch 学習させたのちの "Validation Loss" についても比較してみます。
以下、学習時の引数を変更したときの学習時間、代表的な Epoch における "Validation Loss" の表です。
AI学習は乱数を使っている部分もあるので、私と同じ手順を行っても同じ結果になりません。私自身が同じことを複数回行っても異なる結果になったりします。あくまで参考値ということで。
| Epoch num. | Normal (追加引数無し) |
--freeze_net | --freeze_base_net |
|---|---|---|---|
| 0 | 3.77 | 8.19 | 4.63 |
| 10 | 2.98 | 7.98 | 4.10 |
| 20 | 2.98 | 8.02 | 3.95 |
| 30 | 2.82 | 6.27 | 3.76 |
| 40 | 2.75 | 5.91 | 3.59 |
| 50 | 3.00 | 4.92 | 3.49 |
| 60 | 2.83 | 4.45 | 3.25 |
| 70 | 2.89 | 3.83 | 3.17 |
| 80 | 2.80 | 3.58 | 3.07 |
| 90 | 2.86 | 3.42 | 3.01 |
| 99 | 2.84 | 3.40 | 3.01 |
| 学習時間 | 5時間30分 | 2時間20分 | 2時間40分 |
"--freeze_net", "--freeze_base_net" の学習時間は半分以下になりました。認識結果は Normal より悪いですがそこそこ認識しています。
認識性能(Validation Loss)は Normal が最も良い結果となりました。
それぞれメリット/デメリットがありそうなので、用途などに応じて使い分けてみてはいかがでしょうか。
以下、サンプル画像による認識結果例です。
["Normal" Epoch99 による認識結果例]
["--freeze_net" Epoch99 による認識結果例]

["--freeze_base_net" Epoch99 による認識結果例]

11. スケジューラ "multi-step" を試してみる
"multi-step" は学習速度の減速タイミングを詳細に指示することができます。
スケジューラを「cosine」とした上記学習では、Epoch 30~50 あたりから学習の停滞がみられます。"Validation Loss" の値だと 2.8~2.9 ぐらいから良くなりません。この辺りに達した後、学習速度をさらに減速することでより良い結果を得られるのではという仮説から、スケジューラを「multi-step」へ変更、--milestones として "50,80" を指定して実験してみます。
引数 --milestones で指定した Epoch で学習速度を 0.1倍 へ減速します。下記例は Epoch 0-49 まで初期値、Epoch 50-79 を 0.1倍、Epoch 80-99 をさらに 0.1倍、つまり初期値の 0.01倍へ減速します。
python train_ssd.py --dataset_type open_images --datasets ./data/open_images --net mb1-ssd --pretrained_ssd models/mobilenet-v1-ssd-mp-0_675.pth --scheduler multi-step --milestones 50,80 --lr 0.01 --validation_epochs 5 --num_epochs 100 --base_net_lr 0.001 --batch_size 5
下記表へ Epoch で99までの学習の様子を記載します。1回のみの結果なので、複数回実施するとまた違う結果になるかもしれません。
| Epoch num. | Cosine | Multi-step (50, 80) | ||
|---|---|---|---|---|
| Validation Loss | Average Loss | Validation Loss | Average Loss | |
| 0 | 3.58 | 5.95 | 3.68 | 5.86 |
| 10 | 3.07 | 3.38 | 3.10 | 3.40 |
| 20 | 2.87 | 3.08 | 3.08 | 3.10 |
| 30 | 2.77 | 2.75 | 2.81 | 2.94 |
| 40 | 2.84 | 2.52 | 2.92 | 2.91 |
| 50 | 2.83 | 2.41 | 2.72 | 2.69 |
| 60 | 2.82 | 2.27 | 2.75 | 2.27 |
| 70 | 2.77 | 2.01 | 2.72 | 2.17 |
| 80 | 2.80 | 1.99 | 2.72 | 2.10 |
| 90 | 2.78 | 1.84 | 2.75 | 2.01 |
| 99 | 2.86 | 1.69 | 2.72 | 1.99 |
| 学習時間 | 5時間30分 | 5時間30分 | ||
["multistep" Epoch99 による認識結果例]

少なくとも "multi-step" による学習はできてそうです。枠の位置はこれが最も良い結果に見えます。
5-2. 独自の画像を学習してみる (Pascal/VOC)
[概要]
今度は自身で集めた画像を使ってオリジナルの学習データによる学習を試みます。
前節で使用した train_ssd.py は入力データ型として "open_images" と "voc" の2種類に対応しているようです。ここでは "voc" の出力に対応していて有名なオープンソースツール LabelImg を使用してアノテーションデータを作成してみます。
そして自身で実際に作成したアノテーションデータを使って学習を行ってみます。少なめのデータで技術的に実現できることまでを目標に進めてみたいと思います。認識性能を高くしたい場合は同じ要領で学習する画像データを増やせば良いので、本ページではあくまで手順の確認と説明まで行うことにします。
準備した画像データは以下の通りです。pixabay から入手させていただきました。
全て 商用利用無料、帰属表示必要なし、の画像です。ライセンス詳細は "Pixabay License" を参照ください。
| Class name | TrainVal | Test |
|---|---|---|
| bird | 140 | 60 |
[環境]
| 言語 : | Python, | 3.10.7 3.7.9 |
| PyTorch, | 1.12.1+cpu | |
| OS : | Windows 11 home, | 22H2 |
[手順]
5-2-1. 準備
1. "train_ssd.py" が想定する VOC データセットのフォルダ・ファイルを準備
voc 形式のフォルダおよびファイル構成は下図の通りです。この構成図に従ってフォルダを作成します。

| 名称 | 説明 |
|---|---|
| Annotations | アノテーション結果を記録した XML ファイルを保存します。 |
| JPEGImages | JPEG ファイルを保存します。 |
| ImageSets/Main/test.txt | テスト用ファイルのファイル名一覧を記録します。拡張子なしで記載します。 |
| ImageSets/Main/trainval.txt | 学習用ファイルのファイル名一覧を記録します。拡張子なしで記載します。 |
| labels.txt | ラベル一覧を記録します。 |
2. 学習用の画像を集めて "JPEGImages" フォルダへ保存します。
学習用160枚、テスト用40枚、合計200枚の JPEG ファイルをすべてここに保存しました。
3. "labels.txt" を設定
"labels.txt" にアノテーションで付与した全ラベルを記載します。
ここの実施例ではオブジェクト名として "bird" のみ記載します。複数登録する場合は改行して行毎にオブジェクト名を記載します。
["labels.txt"]
bird
注意
- 対象とするアノテーションデータファイル(*.xml)に記載の全てのラベルを "labels.txt" へ記載する必要があります。記載漏れがあると学習実行時にエラーになるので注意が必要です。
- "labels.txt" の内容は全てアルファベット小文字で表記します。大文字で表記したらエラーになりました。上記例だと "BIRD" と記載してはいけません。
4. 学習済みモデルを保存
本ページを上から順に進めてきた人たちは既に models フォルダに学習済みモデルデータを保存済みと思います。まだの方は、こちらに記載の内容に従って "mobilenet-v1-ssd-mp-0_675.pth" をダウンロードしてください。
5-2-2. アノテーション
5. LabelImg をインストール
アノテーションツール LabelImg をインストールします。pip, setuptools を更新した後、pip で labelimg をインストールします。
$ python -m pip install --upgrade pip setuptools $ pip3 install labelImg
6. LabelImg を起動、設定
LabelImg の起動方法は下記いずれかで行います。
$ labelImg [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
または
$ labelImg
| 項目 | 説明 | 備考 |
|---|---|---|
| [IMAGE_PATH] | JPEG 画像を保存しているパスを指定します。 | 指定なしでも起動後に選択可能です。 |
| [PRE-DEFINED CLASS FILE] | ラベル名を保存しているテキストファイルのパスを指定します。LabelImg でアノテーション時に画面でリストから選択するだけでクラスを選択することが可能になります。 | 使用する場合は起動時に引数として設定する必要があります。 |
ここでは [PRE-DEFINED CLASS FILE] として先に作成した "labels.txt" を指定してみます。私は下記のようなコマンドで LabelImg を起動します。
$ labelimg .\data\voc\JPEGImages .\data\voc\labels.txt
7. LabelImg 設定
起動直後の画面です。[PRE-DEFINED CLASS FILE]を適切に設定していれば当該フォルダ中の最初の画像を表示しているはずです。
下記2つを設定します。
(1) Change Save Dir: アノテーション結果(xml ファイル)を保存するフォルダを設定します。
(2) 出力形式: 「Pascal/VOC」形式を設定します。
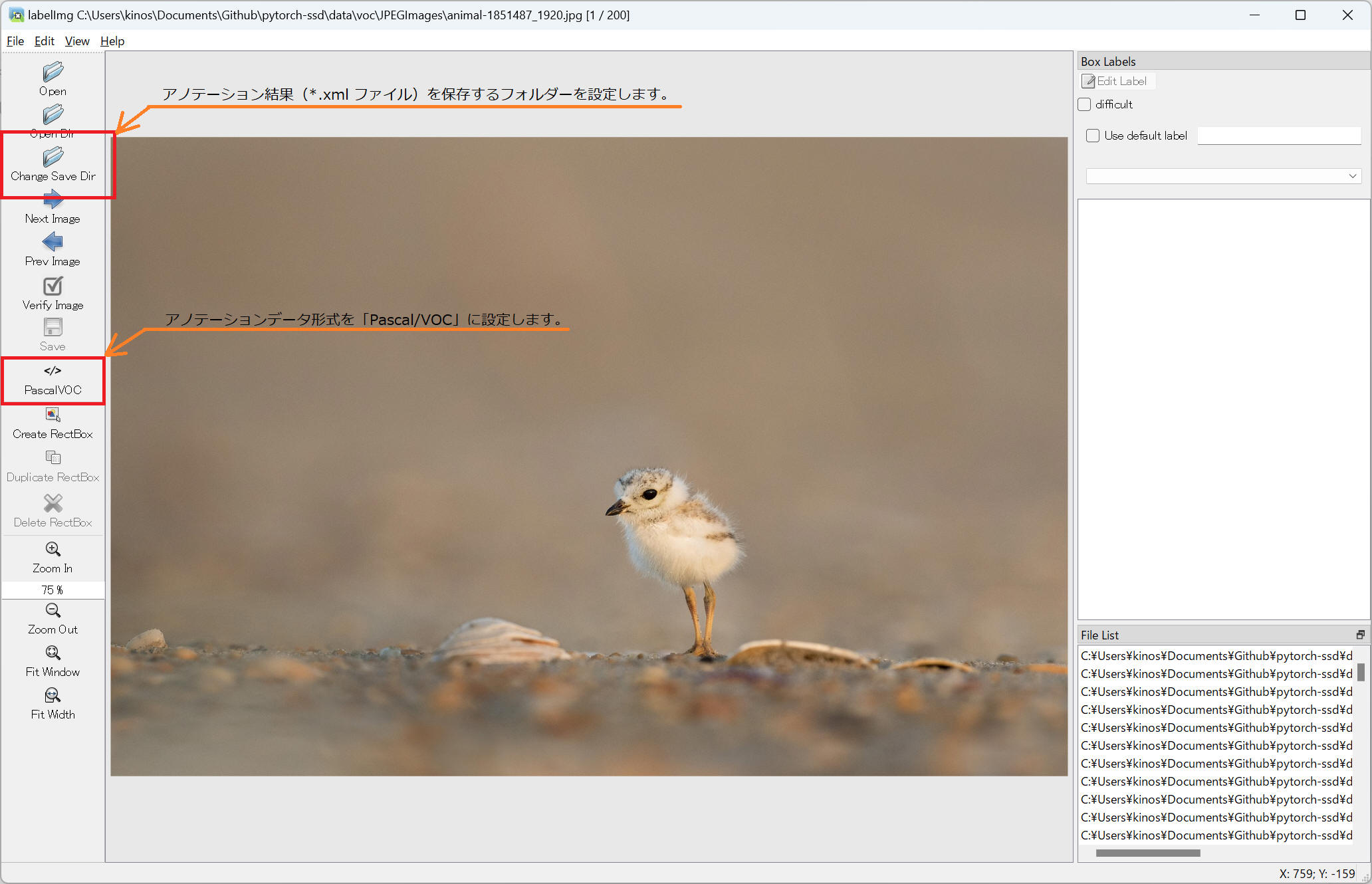
8. LabelImg を使ってアノテーション実施
LabelImg を使ってアノテーションを実施します。こちらは動画で紹介したいと思います。
[動画] アノテーション実施の様子
設定後の枠位置再修正、ラベル変更、なども可能です。実際に出力されたアノテーション結果データを以下に例示します。複数の枠を設定した場合は <object> の情報を複数記録したファイルとなります。
["animal-1851487_1920.xml"]
<annotation>
<folder>JPEGImages</folder>
<filename>animal-1851487_1920.jpg</filename>
<path>C:\Users\[user-name]\Documents\Github\pytorch-ssd\data\voc\JPEGImages\animal-1851487_1920.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1920</width>
<height>1282</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>bird</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>989</xmin>
<ymin>656</ymin>
<xmax>1273</xmax>
<ymax>1048</ymax>
</bndbox>
</object>
</annotation>
参考
私の環境で LabelImg メニューから "View" > "Display Labels" を選択するとアプリケーションを異常終了しました。
"C:\Users\[user-name]\AppData\Local\Programs\Python\Python310\lib\site-packages\libs\shape.py" の131行目の min_x, min_y を int でキャストすることで正常動作するようになりました。
※ この修正なしで正常に動作しました、とご連絡くださった方もいらっしゃいました。
エラー出力内容です。
File "C:\Users\[user-name]\AppData\Local\Programs\Python\Python310\lib\site-packages\libs\shape.py", line 131, in paint
painter.drawText(min_x, min_y, self.label)
TypeError: arguments did not match any overloaded call:
drawText(self, Union[QPointF, QPoint], str): argument 1 has unexpected type 'float'
drawText(self, QRectF, int, str): argument 1 has unexpected type 'float'
drawText(self, QRect, int, str): argument 1 has unexpected type 'float'
drawText(self, QRectF, str, option: QTextOption = QTextOption()): argument 1 has unexpected type 'float'
drawText(self, QPoint, str): argument 1 has unexpected type 'float'
drawText(self, int, int, int, int, int, str): argument 1 has unexpected type 'float'
drawText(self, int, int, str): argument 1 has unexpected type 'float'
"C:\Users\[user-name]\AppData\Local\Programs\Python\Python310\lib\site-packages\libs\shape.py" 131行目 修正後の内容
painter.drawText(int(min_x), int(min_y), self.label)
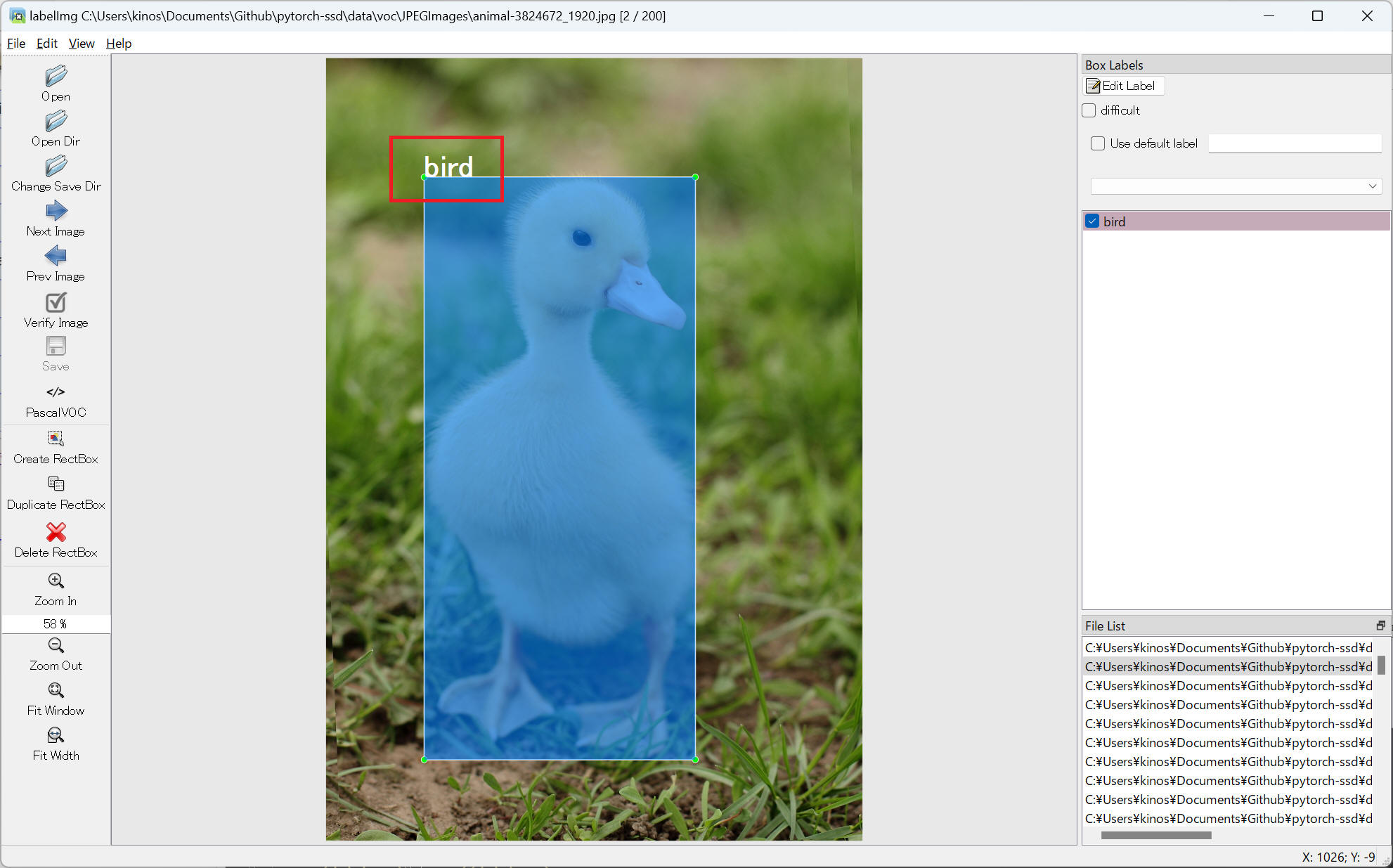
"Display Labels" を有効化した例
5-2-3. "trainval.txt"、"test.txt" を用意
9. "ImageSets\Main\trainval.txt"、"ImageSets\Main\test.txt" を用意します
ここでは全画像データから 70% を学習用("trainval.txt")に、30% を評価用("test.txt")に使用します。各ファイル("trainval.txt", "test.txt")に拡張子を除いたファイル名一覧を記載します。
学習は "trainval.txt" に記載の順序で行うので、ファイル記載順によってデータに偏りが無い方が良いです。このため一般的にはファイルリストをランダムにシャッフルします。
注意
アノテーションでラベル付けをされていない画像を学習および評価に使用することはできませんでした。詳細不明ですが、ラベル付けされていないデータを混ぜると学習時にエラーになりました。検知対象外の物体を学習させる意図で使いたくなる方法ですが、何かしらプログラム改善を必要としそうです。
今回はオブジェクト種類が1つなのでまだ良いのですが、複数の種類を学習するときは種別ごとに適正に配分する必要があるので大変です。今後のことを考えて "trainval.txt" と "test.txt" を自動生成するプログラムを作成してみました。下記にソースコードを記載します。
使用方法概要です。
- 他のプログラムと同様に、下記ソースコードを pytorch-ssd のルートフォルダに保存します。
- 上記に構成したフォルダ構成のままであれば、このプログラムを実行するだけです。
- パスやファイル名を変更する場合、下記表を参考に引数を指定して実行します。
- 学習用・評価用の比率(70%, 30%)を変更したい場合はプログラム中の定数を直接変更してください。
| オプション | 内容 | デフォルト値 |
|---|---|---|
| --jpeg_path | JPEG ファイルを保存するファルダパス | "./data/voc/JPEGImages" |
| --xml_path | XML ファイルを保存するフォルダパス | "./data/voc/Annotations" |
| --imagesets_path | trainval.txt, test.txt を保存するフォルダパス | "./data/voc/ImageSets/Main" |
| --trainval_filename | trainval ファイル名 | "trainval.txt" |
| --test_filename | test ファイル名 | "test.txt" |
'''
[Abstract]
JPEGファイル(*.jpg)、アノテーションファイル(*.xml)から "trainval.txt" "test.txt" を作成する
[Details]
- jpeg_path と xml_path に保存されているファイルを確認して両方に存在するファイルのみでファイルリストを作成する。
- XML ファイルの内容を確認し、対象全ファイル中に存在するクラス名の一覧を作成する。
- クラス毎に "<class_name>_trainval.txt", "<class_name>_test.txt" を作成する。
ファイルの 70% を "<class_name>_trainval.txt" に、30% を "<class_name>_test.txt" に保存する。
- 全ての "<class_name>_trainval.txt" を集めて "trainval.txt" として保存する。ファイル一覧をランダムシャッフルする。
- 全ての "<class_name>_test.txt" を集めて "test.txt" として保存する。ファイル一覧をランダムシャッフルする。
[Author]
kinoshita hidetoshi (木下英俊)
[library install]
下記 import 参照
'''
import argparse
import logging
import sys
import os
import glob
import random
import xml.etree.ElementTree as ET
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
'''
[Abstract]
指定フォルダ中の *.jpg ファイルリストを作成する。
basename(フォルダパス無し)、拡張子無し、の表記とする。
'''
def create_jpeg_list(folder_path):
files_with_path = glob.glob(folder_path + "/*.jpg")
files_without_path_ext = []
for file in files_with_path:
files_without_path_ext.append(os.path.splitext(os.path.basename(file))[0])
return files_without_path_ext
'''
[Abstract]
指定フォルダ中の *.xml ファイルリストを作成する。
basename(フォルダパス無し)、拡張子無し、の表記とする。
'''
def create_xml_list(folder_path):
files_with_path = glob.glob(folder_path + "/*.xml")
files_without_path_ext = []
for file in files_with_path:
files_without_path_ext.append(os.path.splitext(os.path.basename(file))[0])
return files_without_path_ext
'''
[Abstract]
jpeg_files, xml_files の両方に存在するもののみのファイルリストを作成する。
'''
def create_target_list(jpeg_path, xml_path):
'''
JPEG ファイル一覧を作成する
'''
jpeg_files = create_jpeg_list(jpeg_path)
'''
XML ファイル一覧を作成する
'''
xml_files = create_xml_list(xml_path)
'''
JPEG, XML 両方に共通であるものだけをリスト化
'''
target_files = []
for file in jpeg_files:
if file in xml_files:
target_files.append(file)
return target_files
'''
[Abstract]
特定クラス向けの "<class_name>_trainval.txt", "<class_name>_test.txt" を出力する
'''
def save_trainval_test_with_class_name(target_files, class_name):
'''
ファイルリストの 70% を "<class_name>_trainval.txt" へ、30% を "<class_name>_test.txt" へ出力
'''
files_end = len(target_files)
test_end = int(files_end * 0.3)
'''
"<class_name>_test.txt", "<class_name>_trainval.txt" 出力
'''
with open( os.path.join( args.imagesets_path, class_name + '_' + args.test_filename), 'w') as f:
f.write('\n'.join(target_files[0:test_end]))
with open( os.path.join( args.imagesets_path, class_name + '_' + args.trainval_filename), 'w') as f:
f.write('\n'.join(target_files[test_end:files_end]))
'''
[Abstract]
アノテーションファイル(XMLファイル)から "trainval.txt" "test.txt" を作成する
'''
def create_imagesets_files():
'''
JPEG, XML 両方に共通に存在するファイル名だけをリスト化
'''
target_files = create_target_list(args.jpeg_path, args.xml_path)
'''
ラベルリストを作成
'''
label_list = []
for file in target_files:
annotation_file = os.path.join( args.xml_path, file + '.xml')
objects = ET.parse(annotation_file).findall("object")
for object in objects:
#class_name = object.find('name').text.lower().strip()
class_name = object.find('name').text.strip()
if class_name not in label_list:
label_list.append(class_name)
logging.info('=== label_list ===')
logging.info(label_list)
'''
ラベル毎の trainval_<label>.txt, test_<label>.txt を作成
それぞれ全体の 70%, 30% の比率で出力
'''
trainval_files_list = []
test_files_list = []
for label in label_list:
file_list = []
for file in target_files:
annotation_file = os.path.join( args.xml_path, file + '.xml')
objects = ET.parse(annotation_file).findall("object")
for object in objects:
class_name = object.find('name').text.strip()
if class_name == label:
file_list.append(file)
break
save_trainval_test_with_class_name(file_list, label)
trainval_files_list.append( label + '_' + args.trainval_filename)
test_files_list.append( label + '_' + args.test_filename)
'''
<label>_trainval.txt を全て結合し、trainval.txt を作成
ファイルリストはランダムソート後に出力
'''
trainval_files = []
for file in trainval_files_list:
with open( os.path.join( args.imagesets_path, file), 'r') as f:
for line in f:
trainval_files.append(line.strip())
random.shuffle(trainval_files)
filename = os.path.join( args.imagesets_path, args.trainval_filename)
with open( filename, 'w') as f:
f.write('\n'.join(trainval_files))
logging.info('=== trainval.txt ===')
logging.info('path : ' + filename)
logging.info('size : ' + str(len(trainval_files)))
'''
<label>_test.txt を全て結合し、test.txt を作成
ファイルリストはランダムソート後に出力
'''
test_files = []
for file in test_files_list:
with open( os.path.join( args.imagesets_path, file), 'r') as f:
for line in f:
test_files.append(line.strip())
random.shuffle(test_files)
filename = os.path.join( args.imagesets_path, args.test_filename)
with open( filename, 'w') as f:
f.write('\n'.join(test_files))
logging.info('=== test.txt ===')
logging.info('path : ' + filename)
logging.info('size : ' + str(len(test_files)))
'''
[Abstract]
main 関数
'''
if __name__ == '__main__':
parser = argparse.ArgumentParser( description='Create "ImageSets/Main/trainval.txt", "ImageSets/Main.test.txt" files.')
parser.add_argument("--jpeg_path", default="./data/voc/JPEGImages", type=str, help='Specify JPEGImages (jpeg files) path.')
parser.add_argument("--xml_path", default="./data/voc/Annotations", type=str, help='Specify Annotations (xml files) path.')
parser.add_argument("--imagesets_path", default="./data/voc/ImageSets/Main", type=str, help='Specify ImageSets path.')
parser.add_argument("--trainval_filename", default="trainval.txt", type=str, help='Specify trainval.txt filename.')
parser.add_argument("--test_filename", default="test.txt", type=str, help='Specify test.txt filename.')
args = parser.parse_args()
logging.info('=== args ===')
logging.info(args)
if os.path.exists( args.jpeg_path ) == False:
print("NOT exist " + args.jpeg_path + ".")
sys.exit(1)
if os.path.exists( args.xml_path ) == False:
print("NOT exist " + args.xml_path + ".")
sys.exit(1)
if os.path.exists( args.imagesets_path ) == False:
print("NOT exist " + args.imagesets_path + ".")
sys.exit(1)
create_imagesets_files()
実行後のログ出力例です。
2023-02-16 17:48:25,323 - root - INFO - === args === 2023-02-16 17:48:25,323 - root - INFO - Namespace(jpeg_path='./data/voc/JPEGImages', xml_path='./data/voc/Annotations', imagesets_path='./data/voc/ImageSets/Main', trainval_filename='trainval.txt', test_filename='test.txt') 2023-02-16 17:48:25,361 - root - INFO - === label_list === 2023-02-16 17:48:25,362 - root - INFO - ['bird'] 2023-02-16 17:48:25,388 - root - INFO - === trainval.txt === 2023-02-16 17:48:25,388 - root - INFO - path : ./data/voc/ImageSets/Main\trainval.txt 2023-02-16 17:48:25,389 - root - INFO - size : 140 2023-02-16 17:48:25,395 - root - INFO - === test.txt === 2023-02-16 17:48:25,395 - root - INFO - path : ./data/voc/ImageSets/Main\test.txt 2023-02-16 17:48:25,395 - root - INFO - size : 60
注意
ログ出力を確認し、意図通りのオブジェクト名(ここでは ['bird'] の部分)のみであることを確認しましょう。意図しないオブジェクト名があるとこの後の学習でエラーの原因となります。
同様に各出力枚数についても確認し、あなたの期待する値と一致することを確認しましょう。
"trainval.txt" 出力例です。
grey-heron-6318054_1920 bird-g0919a497b_1920 crows-7381423_1920 kingfisher-gc64d47593_1920 rooster-1867562_1920 blue-tit-6908151_1920 bird-9950_1920 tit-4987149_1920 seagull-4841143_1920 mallard-3524390_1920 kingfisher-881975_1920 seagull-640229_1920 hd-wallpaper-2566241_1920 robin-6619184_1920 deckchairs-355596_1920 falcon-1264605_1920 seagull-5289474_1920 kingfisher-1867936_1920 sparrows-2763553_1920 flamingo-6126763_1920 ・・・
"test.txt" 出力例です。
bird-6983434_1920 bird-4087736_1920 bird-5965265_1920 bird-7000837_1920 bird-4062359_1920 barn-owl-1107397_1920 bird-4198001_1920 bird-4401223_1920 bird-4563886_1920 bird-349026_1920 bird-2847799_1920 bird-7356346_1920 bird-1213447_1920 bird-6721895_1920 bird-173584_1920 bird-7145813_1920 bird-5981360_1920 bird-7299650_1920 animal-1851487_1920 bird-7016926_1920 ・・・
以上で学習のための事前準備を完了です。
5-2-4. 学習
10. 学習を実施
下記コマンドにより学習を実行しました。
$ python train_ssd.py --dataset_type voc --datasets ./data/voc --validation_dataset ./data/voc --net mb1-ssd --pretrained_ssd models/mobilenet-v1-ssd-mp-0_675.pth --scheduler cosine --lr 0.01 --t_max 100 --validation_epochs 5 --num_epochs 100 --debug_steps 25 --base_net_lr 0.001 --batch_size 5
| オプション | 設定値 | 補足 |
|---|---|---|
| --dataset_type | voc | Pascal/VOC 型のアノテーションデータセットを使用。 |
| --datasets | ./data/voc | |
| --validation_dataset | ./data/voc | |
| --net | mb1-ssd | MobileNet-SSD v1 |
| --pretrained_ssd | model/mobilenet-v1-ssd-mp-0_675.pth | Pretrained base model. |
| --scheduler | cosine | Scheduler for SGD. It can one of multi-step and cosine. |
| --lr | 0.01 | initial learning rate. |
| --base_net_lr | 0.001 | initial learning rate for base net. |
| --t_max | 100 | T_max value for Cosine Annealing Scheduler. |
| --validation_epochs | 5 | 評価(validation)を行う Epoch 周期 |
| --num_epochs | 100 | 学習回数。1 Epoch 毎に全ての学習画像で訓練する。今回の例だと、140枚の画像を使って100回反復することを意味する。 |
| --batch_size | 5 | 訓練一回で使用する画像枚数。この1回を step と呼ぶようです。 |
| --debug_steps | 25 | Set the debug log output frequency. 今回の例では 学習データ数が 140、バッチサイズが 5 なので、1 Epoch 毎に 28回(28 step)の訓練を行います。 各 Epoch で一回のデバッグ出力をして欲しい、という意図から適当ではありますがここでは 25 という値を設定しました。15~28 から選べば各1回のデバッグ出力を行えるはずです。逆に 28 より大きい値を設定するとデバッグ出力無しになります。 |
下記表に学習時の精度遷移を参考記載します。
| Epoch num. | Validation Loss | Average Loss |
|---|---|---|
| 0 | 4.67 | 6.15 |
| 10 | 2.74 | 2.35 |
| 20 | 2.78 | 2.11 |
| 30 | 2.48 | 1.83 |
| 40 | 2.40 | 1.60 |
| 50 | 2.18 | 1.50 |
| 60 | 2.15 | 1.28 |
| 70 | 2.13 | 1.24 |
| 80 | 2.16 | 1.33 |
| 90 | 2.09 | 1.16 |
| 99 | 2.07 | 1.22 |
| 学習時間 | 52分 (CPU 環境) | |
52分(CPU 環境)で "100 Epoch" の学習を完了できました。
学習データと共に出力された "models/voc-model-labels.txt" の内容を以下に記載します。
["models/voc-model-labels.txt" の内容]
BACKGROUND bird
参考
ゲーミングノートPC環境でも同じ学習を実施。
52分 ⇨ 22分 へ短縮できました。
[環境]
GPU: NVIDIA GeForce GTX 1650 (4GB)
CPU: Intel Core i7-9750H
Cuda: 11.6
Python: 3.10.7
PyToch: 1.12+cu116
OS: Windows 11 home, 22H2
5-2-5. 学習結果と静止画を使って推論
11. 学習したデータとテスト画像を使用して認識
私の学習済みデータ("mb1-ssd-Epoch-99-Loss-2.0738580177227655.pth")とサンプル画像("birds-7469509_1920.jpg")を使った コマンド実施例 を以下に記載します。あなたが実際に使用するファイル名およびパスへ修正してください。
(コマンド書式)
$ python run_ssd_example.py mb1-ssd <学習データファイル パス> <ラベルファイル パス> <認識対象画像 パス>
(具体例)
$ python run_ssd_example.py mb1-ssd .\models\mb1-ssd-Epoch-99-Loss-2.0738580177227655.pth .\models\voc-model-labels.txt .\data\voc\JPEGImages\birds-7469509_1920.jpg
以下、いくつかのサンプル画像による認識結果です。
テスト画像1: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の画像です。ライセンス詳細は "Pixabay License" を参照ください。
["birds-7469509_1920.jpg"]

テスト画像2: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の画像です。ライセンス詳細は "Pixabay License" を参照ください。
["gray-heron-5077089_1920.jpg"]

テスト画像3: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の画像です。ライセンス詳細は "Pixabay License" を参照ください。
["eurasian-wigeon-4914971_1920.jpg"]

今回学習に使用した画像枚数は 140枚 という少ないものでしたが、私の予想に反してそこそこ以上の良い認識性能を実現できました。
学習済みデータを元に追加学習を行っていることも効率よく学習できた大きな要因でしょう。短い時間で学習できているのは軽量型のAIモデル(MobileNet)を使っていることも理由の1つでしょう。
少ない学習画像枚数、短い学習時間で実現できました。正常認識できない画像を収集して追加学習すればさらなる認識性能向上も見込めます。様々な応用を考えることができそうと思いました。AIを学習したり応用したい人達の参考になれば幸いです。
5-2-6. 学習結果とカメラを使って物体検知してみる (i-PRO カメラ)
[概要]
前節で作成した学習結果とカメラを使って物体検知を行ってみます。
[環境]
| 言語 : | Python, | 3.10.7 3.7.9 |
| PyTorch, | 1.12.1+cpu | |
| OS : | Windows 11 home, | 22H2 |
[手順]
記事「2-2. MobileNetV1-SSD を動かす(i-PRO カメラ)」の内容に従って行います。
元の記事内容からラベルと学習データを変更するだけで、あなたが作成した学習データによる物体検知を行うことができます。
環境構築などは既にできていることを前提に詳細説明を割愛します。
下記コマンドを入力してプログラムを起動します。
- <学習データファイル パス>、<ラベルファイル パス> にあなたが作成したファイルのパスを記載します。
- 4番目の引数として RTSP 表記で i-PRO カメラの接続を記載します。{user-id},
{password}, {ip-address}
の部分をご自身が使われる i-PRO カメラの設定に合わせて修正して実行してください。
その他 RTSP に関しては記事「RTSP で画像を取得する」を参照ください。
(コマンド書式)
$ python run_ssd_live_demo.py mb1-ssd <学習データファイル パス> <ラベルファイル パス> rtsp://{user-id}:{password}@{ip-address}/MediaInput/stream_1
(具体例)
$ python run_ssd_live_demo.py mb1-ssd models/mb1-ssd-Epoch-99-Loss-2.0738580177227655.pth models/voc-model-labels.txt rtsp://userid:Password12345@192.168.0.10/MediaInput/stream_1
以下、いくつかのサンプル動画による認識結果です。
※ PC上で再生表示する動画を i-PRO カメラで接写してテストしています。このため画質が荒くなっていますこと、ご容赦ください。
テスト動画1: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の動画です。ライセンス詳細は "Pixabay License" を参照ください。
[動画] テスト動画1
テスト動画2: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の動画です。ライセンス詳細は "Pixabay License" を参照ください。
[動画] テスト動画2
テスト動画3: 入手元 Pixabay
商用利用無料、帰属表示必要なし、の動画です。ライセンス詳細は "Pixabay License" を参照ください。
[動画] テスト動画3
今回学習に使用した画像枚数は 140枚 という少ないものでしたが、私の予想に反してそこそこ以上の良い認識性能を実現できました。